Stable Diffusion Review: Open-Source AI Image Generation Explained
The landscape of digital creativity has been irrevocably altered by the rise of artificial intelligence. Among the most transformative technologies to emerge is AI image generation, a field that has captured the imagination of artists, marketers, and developers alike. At the forefront of this revolution is Stable Diffusion, a powerful, open-source model that has democratized the creation of high-quality, AI-generated images. This article provides a comprehensive review of the model, exploring its underlying technology, comparing it to alternatives, and examining its vast potential across various industries.
What is Stable Diffusion? An In-Depth Look
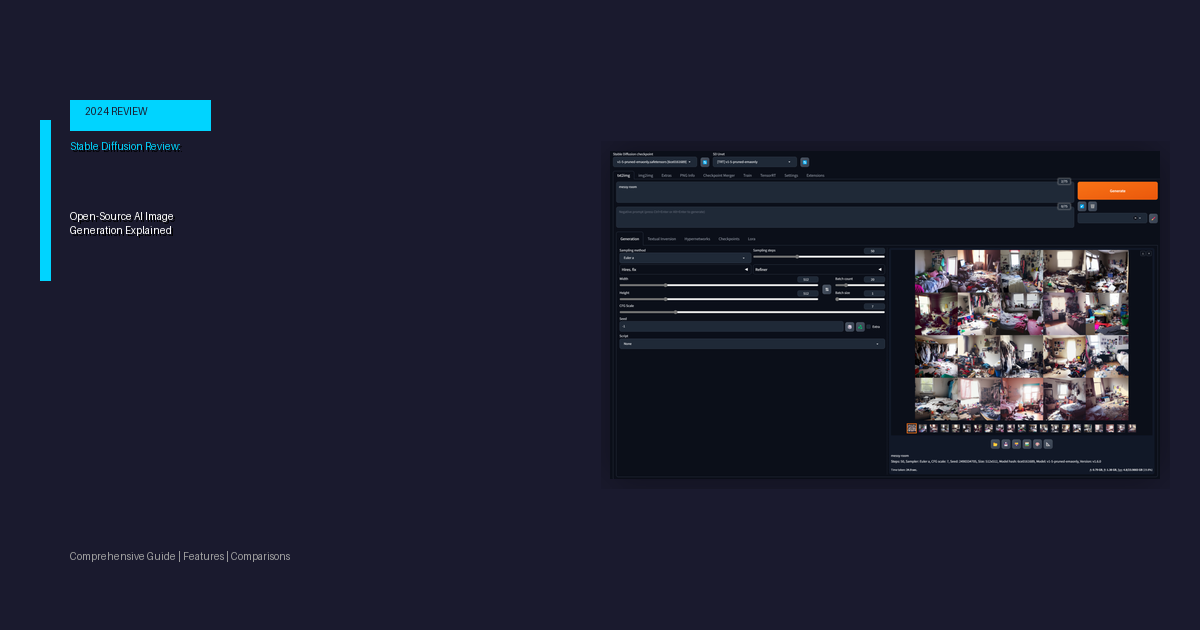
Stable Diffusion is a state-of-the-art, open-source model for text-to-image synthesis released by Stability AI in 2022. Unlike many of its proprietary counterparts, it provides users with unprecedented access to its code and model weights, fostering a vibrant community of developers and artists who continuously expand its capabilities. This commitment to open-source AI has been a driving force behind its widespread adoption and innovation.
The core of the model is its architecture, which is based on a latent diffusion model (LDM). In simple terms, the model learns to create images by reversing a process of adding noise. It starts with a random noise image in a compressed, lower-dimensional "latent" space and gradually "denoises" it, guided by a text prompt, until a coherent image that matches the description is formed. This process, as detailed in the original research from the CompVis group at LMU Munich, is highly efficient and allows the model to run on consumer-grade hardware, a significant advantage over other resource-intensive models.
Key Features and Capabilities
One of its primary strengths lies in its extensive feature set, which caters to a wide range of users, from hobbyists to enterprise teams. The model is renowned for its high degree of prompt fidelity, allowing for the creation of highly specific and detailed images. Its open-source AI nature also means it is incredibly customizable.

Stable Diffusion vs. The Competition
The field of AI image generation is crowded with impressive models. Understanding how it compares to these image generation alternatives is key to choosing the right tool for the job.
Generative Adversarial Networks (GANs)
Before diffusion models rose to prominence, generative adversarial networks (GANs) were the dominant technology for image synthesis. As explained by researchers at an international journal, GANs consist of two neural networks—a generator and a discriminator—that compete against each other to create realistic images. While GANs can produce highly detailed results, they are notoriously difficult to train and prone to issues like "mode collapse," where the generator produces a limited variety of outputs. Diffusion models like Stable Diffusion are generally more stable to train and offer greater diversity in their generated images, making them more reliable for a wider range of creative AI applications.
Midjourney and DALL-E 3
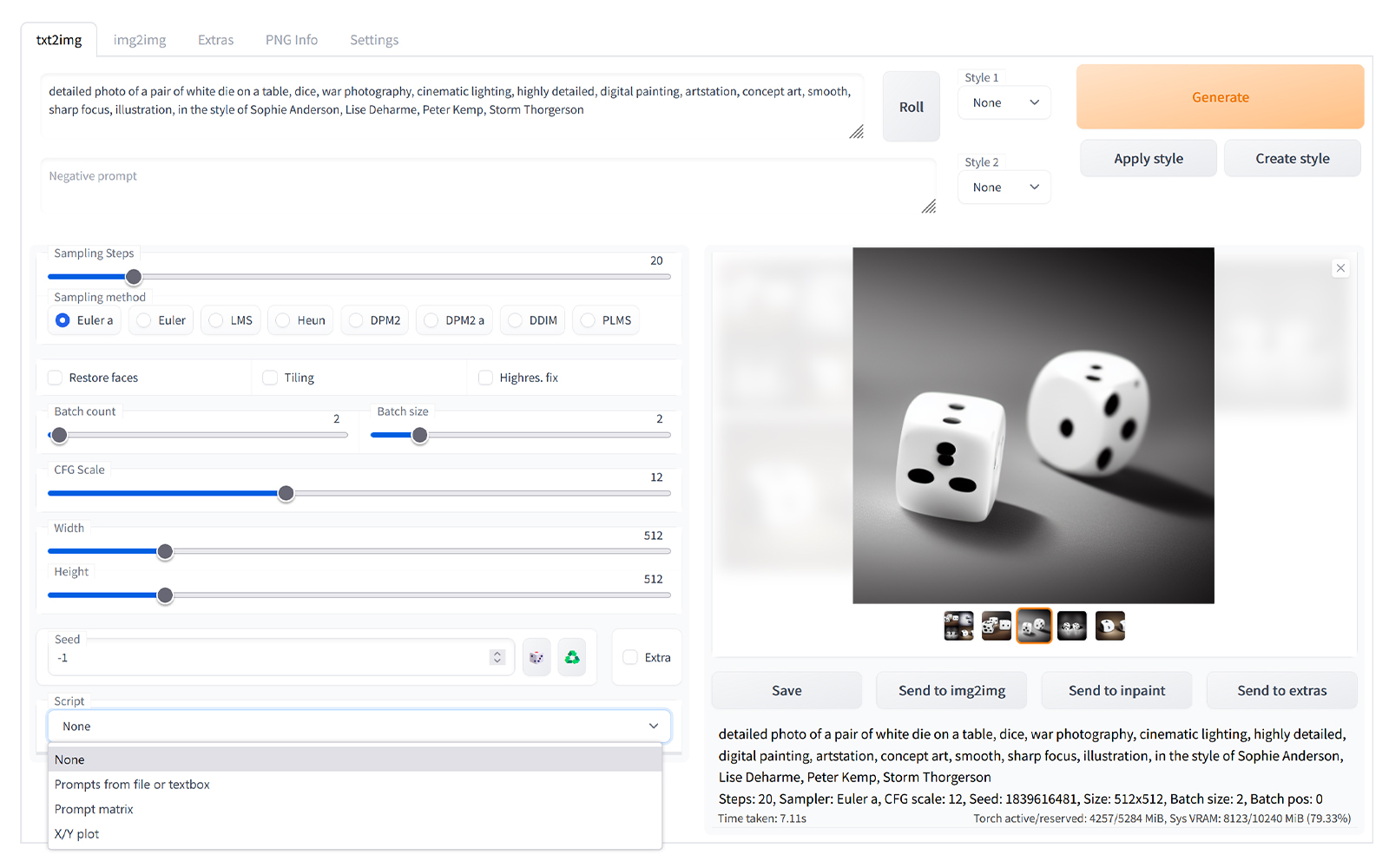
Midjourney and DALL-E 3 are two of the most popular proprietary image generation alternatives. The table below highlights their key differences from Stable Diffusion:
While Midjourney excels at creating beautiful, artistic images with minimal effort, and DALL-E 3 offers unparalleled ease of use, this open-source model remains the top choice for users who require deep control, customization, and the ability to run the model in their own environment.
Creative and Business Applications
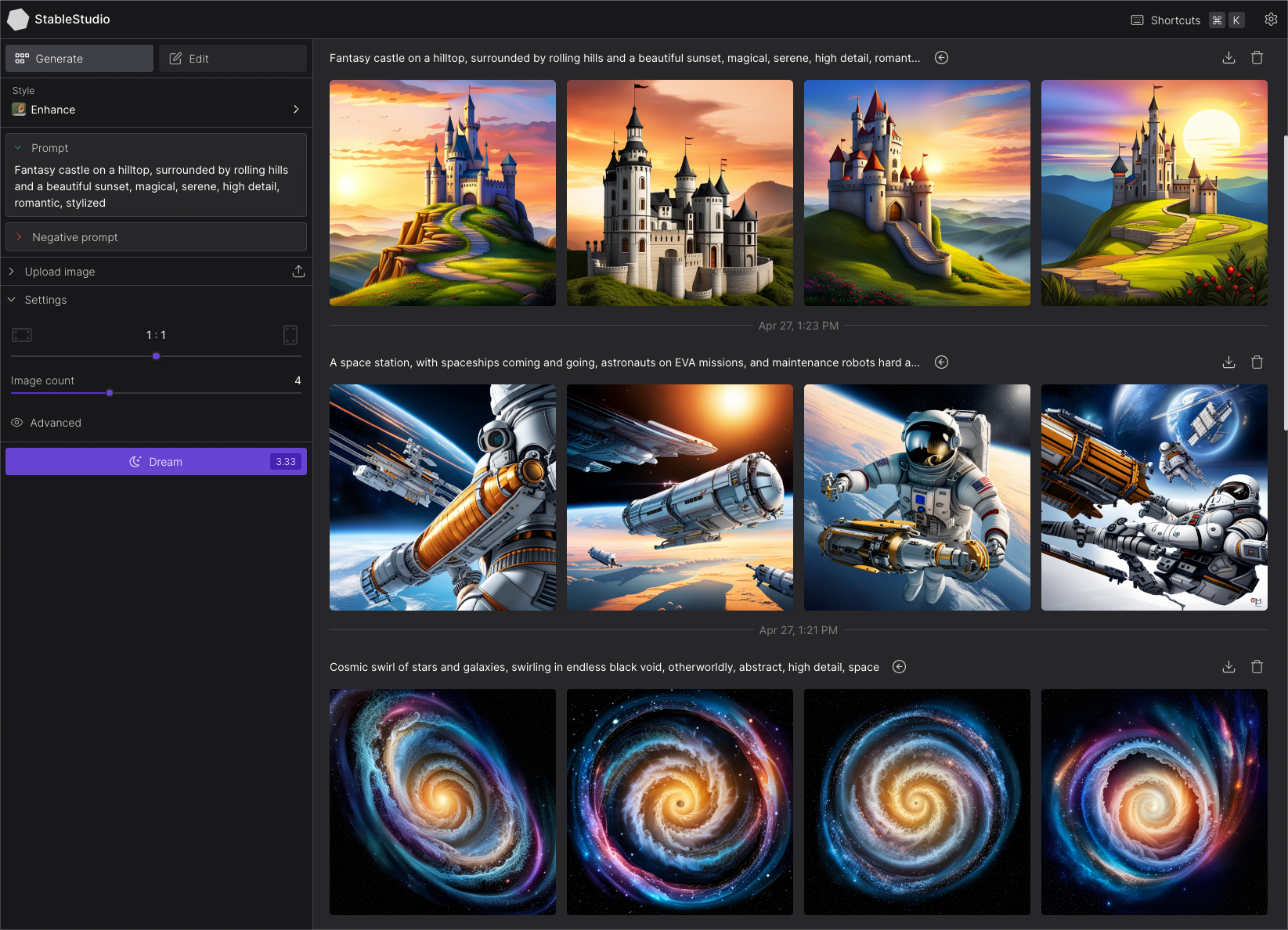
The model's versatility has led to its adoption in a wide array of fields, far beyond just creating art. Its impact is being felt in digital marketing, e-commerce trends, and even in highly technical domains like financial technology and cybersecurity, where it can be used for data visualization and synthetic data generation.
In the realm of creative AI applications, artists are using the tool to explore new visual styles and accelerate their workflows. Designers are leveraging it to quickly generate mockups and prototypes, improving the overall user experience design process. The technology is also finding a place in entertainment, with applications in film pre-visualization and the creation of assets for virtual reality experiences.
For businesses, the ability to generate on-brand imagery at scale is a game-changer. Marketing teams can create endless variations of ad creatives, social media posts, and website visuals, all while maintaining brand consistency through custom-trained models. This has profound implications for efficiency and cost savings.
The Future of Open-Source AI
Stable Diffusion is more than just a powerful tool; it represents a philosophical shift towards a more open and collaborative future for artificial intelligence. By making its technology accessible to all, Stability AI has empowered a global community to innovate and push the boundaries of what is possible. The rapid evolution of the model, driven by both the core developers and the community, is a testament to the power of open-source AI.
However, the rise of powerful generative models also brings challenges. Concerns around data privacy, the potential for misuse, and the ethical implications of AI-generated content are all valid and require careful consideration. The development of technologies like blockchain technology may one day play a role in verifying the authenticity of digital media and addressing some of these concerns.
As we look to the future, the continued development of such models will undoubtedly unlock new possibilities in fields we are only beginning to imagine. From advancements in cloud computing that make these models even more accessible to new breakthroughs in software development that integrate AI at a fundamental level, the journey of AI image generation is just getting started.
Understanding the Latent Diffusion Model Architecture
The latent diffusion model that powers Stable Diffusion represents a significant breakthrough in the efficiency of AI image generation. Traditional diffusion models operate directly in pixel space, which requires enormous computational resources and makes them impractical for most users. By contrast, the latent diffusion model compresses images into a lower-dimensional latent space before applying the diffusion process, dramatically reducing the computational requirements while maintaining high-quality outputs.
This architecture consists of three primary components working in harmony. The Variational Autoencoder (VAE) serves as the bridge between pixel space and latent space, compressing images into a more manageable representation that captures their essential semantic features. The U-Net architecture, which forms the heart of the denoising process, iteratively removes noise from the latent representation, guided by the conditioning information. Finally, the text encoder, typically based on the CLIP model, translates natural language prompts into a format that the U-Net can understand and use to guide the generation process.
This innovative approach to text-to-image synthesis has made it possible for Stable Diffusion to run on consumer hardware with as little as 4GB of VRAM, opening up the technology to a much broader audience than was previously possible with earlier generation models. The efficiency gains are not merely incremental; they represent a fundamental shift in how we approach generative modeling, making powerful AI art tools accessible to anyone with a modern gaming computer.
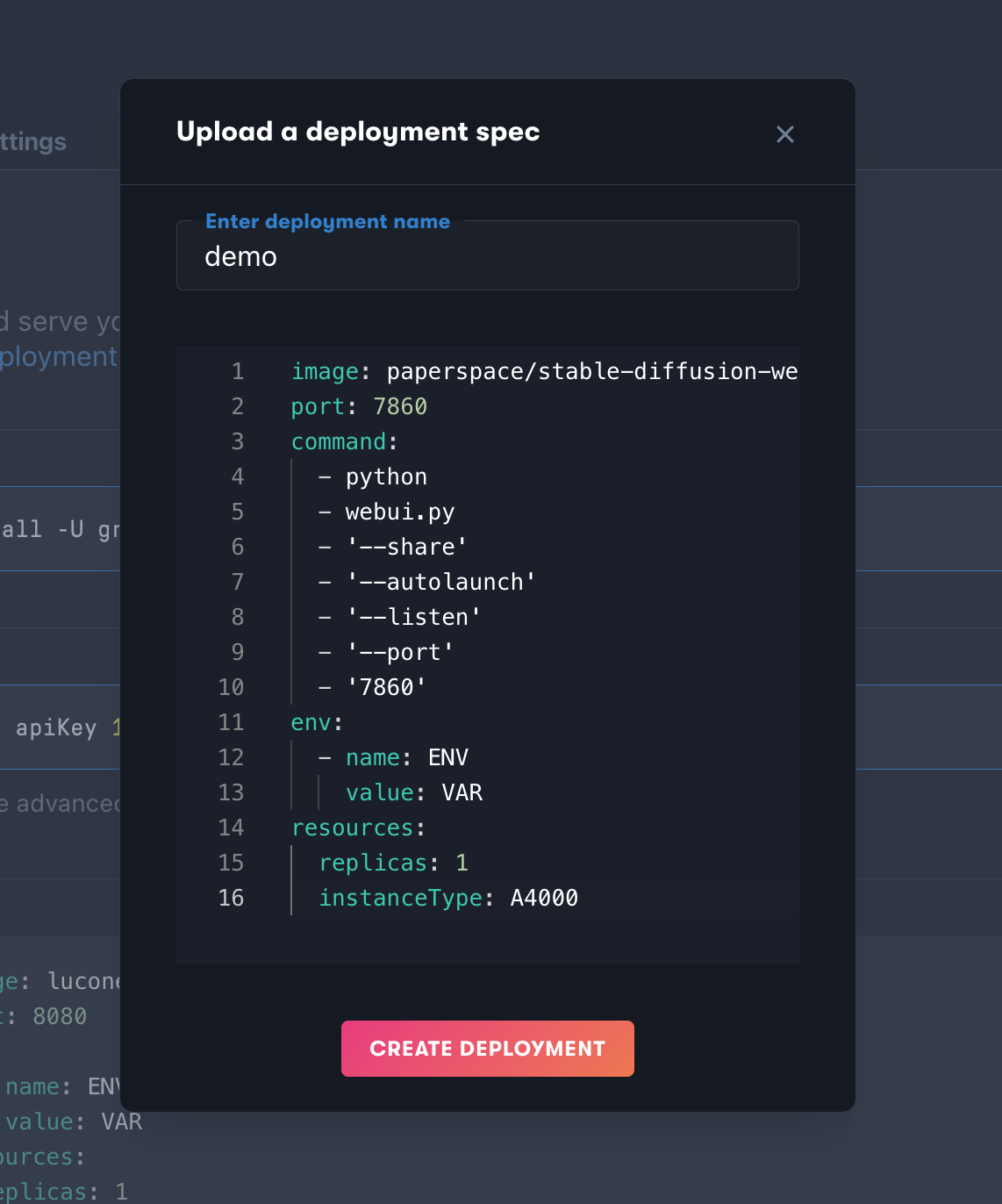
Practical Implementation and Deployment Options
One of the most compelling aspects of Stable Diffusion is the variety of ways it can be deployed, each offering distinct advantages depending on the user's needs and technical expertise. Understanding these options is crucial for anyone looking to integrate AI image generation into their workflow.
Cloud-Based Solutions
For users who prefer immediate access without technical setup, cloud-based platforms like DreamStudio provide a polished interface for generating images with Stable Diffusion. These platforms handle all the infrastructure requirements, allowing users to focus purely on the creative process. This approach is particularly valuable for digital marketing teams that need to quickly generate visual content without investing in specialized hardware or technical expertise. The pay-per-use pricing model also aligns well with variable workloads, ensuring that organizations only pay for what they actually use.
Cloud deployment also offers advantages in terms of cloud computing scalability. During periods of high demand, such as major marketing campaigns or product launches, teams can generate thousands of images without worrying about local hardware limitations. This flexibility is increasingly important in modern e-commerce trends, where the ability to rapidly test and iterate on visual content can provide a significant competitive advantage.
Local Installation and Self-Hosting
For users who prioritize control, data privacy, and long-term cost efficiency, local installation of Stable Diffusion offers unparalleled benefits. Running the model on your own hardware eliminates ongoing subscription costs and ensures that sensitive data never leaves your infrastructure, a critical consideration for industries subject to strict regulatory requirements.
The software development community has created numerous tools and interfaces to make local installation more accessible. Projects like AUTOMATIC1111's Web UI and ComfyUI provide sophisticated interfaces that rival commercial offerings while maintaining the flexibility and customization options that make open-source AI so powerful. These tools have become essential components of the Stable Diffusion ecosystem, demonstrating the value of community-driven development.
Local deployment also enables advanced customization through fine-tuning and model training. Organizations can create proprietary models trained on their specific visual assets, ensuring perfect brand consistency across all generated content. This capability has proven particularly valuable in user experience design, where maintaining a cohesive visual language across all touchpoints is essential for building strong brand recognition.
Advanced Techniques and Workflows
As users become more familiar with Stable Diffusion, they often discover advanced techniques that dramatically enhance the quality and control of their outputs. These methods represent the cutting edge of creative AI applications and demonstrate the depth of capability hidden within the model.
ControlNet and Precise Composition
ControlNet represents one of the most significant advances in controllable AI image generation. This technology allows users to guide the generation process using reference images that define specific aspects of the composition, such as pose, depth, or edge structure. For example, a designer working on a new product visualization can provide a rough sketch or 3D render as a ControlNet input, and Stable Diffusion will generate a photorealistic image that maintains the exact composition while adding realistic details and textures.
This level of control bridges the gap between traditional design workflows and AI-assisted creation, making Stable Diffusion a valuable tool for professional designers who need predictable results. The technology has found applications in fields ranging from virtual reality content creation, where maintaining consistent spatial relationships is crucial, to financial technology applications, where precise data visualizations need to be both accurate and aesthetically compelling.
Fine-Tuning and Custom Models
The ability to fine-tune Stable Diffusion on custom datasets represents one of its most powerful features for professional applications. Through techniques like LoRA (Low-Rank Adaptation) and DreamBooth, users can teach the model to understand specific concepts, styles, or objects that weren't present in the original training data. This capability has transformed how businesses approach visual content creation, enabling them to maintain perfect brand consistency across thousands of generated images.
The process of fine-tuning has become increasingly accessible, with tools and tutorials making it possible for non-experts to create custom models. Marketing agencies are using this capability to create brand-specific versions of Stable Diffusion for each client, ensuring that every generated image perfectly matches the client's visual identity. This approach has proven particularly effective in digital marketing campaigns, where maintaining brand consistency across multiple channels and touchpoints is essential for building recognition and trust.
Industry-Specific Applications and Use Cases
The versatility of Stable Diffusion has led to its adoption across a remarkably diverse range of industries, each finding unique ways to leverage AI image generation to solve specific challenges and create new opportunities.
E-Commerce and Product Visualization
In the rapidly evolving world of e-commerce trends, the ability to quickly generate high-quality product images has become a critical competitive advantage. Stable Diffusion enables retailers to create lifestyle images, contextual product shots, and variations without the expense and logistics of traditional photography. A furniture retailer, for example, can generate images of their products in dozens of different room settings, helping customers visualize how items would look in their own homes.
The technology is also being used to create seasonal variations of product images, allowing retailers to maintain fresh, relevant visual content throughout the year without repeated photography sessions. This application demonstrates how AI art tools are not just replacing traditional methods but enabling entirely new approaches to visual merchandising that would be economically infeasible using conventional techniques.
Cybersecurity and Synthetic Data Generation
In the field of cybersecurity, Stable Diffusion is finding unexpected applications in the generation of synthetic training data. Security systems that rely on computer vision, such as facial recognition or threat detection systems, require vast amounts of diverse training data. Stable Diffusion can generate synthetic images that help train these systems while avoiding privacy concerns associated with using real images of people or sensitive locations.
This application extends to other security-related fields as well. Organizations developing data privacy solutions are using generative models to create realistic but entirely synthetic datasets for testing and development, ensuring that no actual personal information is ever exposed during the development process. This approach represents a significant advancement in how we balance the need for realistic test data with the imperative to protect individual privacy.
Financial Technology and Data Visualization
The financial technology sector is discovering innovative applications for AI image generation in the realm of data visualization and client communications. Stable Diffusion can be used to create custom illustrations for financial reports, generate visual metaphors for complex financial concepts, and produce personalized visual content for client presentations. The ability to quickly generate high-quality, on-brand visuals helps fintech companies communicate complex information more effectively and build stronger relationships with their clients.
Some forward-thinking organizations are even exploring the use of Stable Diffusion in conjunction with blockchain technology to create verifiable, unique visual representations of digital assets or financial instruments. This convergence of technologies demonstrates how AI image generation is becoming integrated into broader technological ecosystems, creating new possibilities that extend far beyond simple image creation.
Ethical Considerations and Responsible Use
The power and accessibility of Stable Diffusion bring with them important ethical considerations that users and organizations must carefully navigate. As AI image generation becomes more sophisticated and widespread, questions around copyright, authenticity, and responsible use have moved to the forefront of discussions about the technology.
The training data for Stable Diffusion was drawn from large-scale internet datasets, raising questions about the rights of artists whose work may have been included in that training data. While the legal landscape is still evolving, responsible users should be mindful of these concerns and consider the ethical implications of their use of the technology. Many organizations are developing internal guidelines for the use of AI art tools, ensuring that they complement rather than replace human creativity and that proper attribution is given when appropriate.
The potential for misuse of AI image generation technology is another critical concern. The ability to create realistic images of people or events that never occurred raises serious questions about authenticity and trust in visual media. This challenge intersects with broader concerns about cybersecurity and information integrity, as malicious actors could potentially use these tools to create convincing fake images for fraud or disinformation campaigns. The development of detection tools and authentication systems, potentially leveraging blockchain technology for provenance tracking, will be essential for maintaining trust in digital media.
